預金通帳を会計ソフトへ入力する・・・・実にメンドクサイ。
もういい加減ネットバンクにしようよ、と思うわけだが。
法人や個人事業用のネットバンクは利用料が高かったり、使い勝手が悪かったり、Windows限定とかIE限定とか制限があったりでまだ使っていないというケースも多いはず。
あるいはネットバンクそのものに対してセキュリティ的に不安を感じていたりとか。
てなわけで、残念ながら預金通帳の利用はまだしばらく続きそうな感じ。
ただ、預金通帳を1行1行会計ソフトへ入力していくという作業に完全に飽きてしまった私としては、なんとかならないか、と。
そこで、すぐに思いつくのが通帳をスキャンしてOCRにかけてデータ化するというもの。
すぐにでも出来ると思ったし、既にやってるケースも多いだろうとググッてみたが意外とその関係の情報は多くない。
なんだかアヤシイ(?)名前のソフトがヒットしたが、体験版はなく、しかもなかなか良いお値段だったので断念。
法人や個人事業用のネットバンクは利用料が高かったり、使い勝手が悪かったり、Windows限定とかIE限定とか制限があったりでまだ使っていないというケースも多いはず。
あるいはネットバンクそのものに対してセキュリティ的に不安を感じていたりとか。
てなわけで、残念ながら預金通帳の利用はまだしばらく続きそうな感じ。
ただ、預金通帳を1行1行会計ソフトへ入力していくという作業に完全に飽きてしまった私としては、なんとかならないか、と。
そこで、すぐに思いつくのが通帳をスキャンしてOCRにかけてデータ化するというもの。
すぐにでも出来ると思ったし、既にやってるケースも多いだろうとググッてみたが意外とその関係の情報は多くない。
なんだかアヤシイ(?)名前のソフトがヒットしたが、体験版はなく、しかもなかなか良いお値段だったので断念。
そんな中、こちらのサイトは割と詳しく解説があったので参考にさせて頂いた。
視覚障碍者向けにOCRソフトをいろいろ比較して解説してくれている。
とりあえずイチオシ?の読取革命というソフトを購入し試してみた。
だが、すぐに満足行く結果が出た訳ではなく、「きっと文字認識辞書を鍛えればそのうち使えるようになるはず!」と日々OCRをかけては文字を登録しまくった。
が・・・・思ったほど上手くいかない。
文字認識の精度もさることながら、レイアウト的な問題で不満が残る。
認識データを吐き出した時にキレイに表形式にならないのだ。
表の自動認識機能もイマイチな気がしてきた。
文字認識の精度もさることながら、レイアウト的な問題で不満が残る。
認識データを吐き出した時にキレイに表形式にならないのだ。
表の自動認識機能もイマイチな気がしてきた。
OCRの対象となる文書によってはこちらのソフトは精度が高いかも知れないが、通帳のOCRとなるとちょっと力不足の感が。
が・・・・まだ諦め切れない。
次に試したのがメディアドライブ社の「e.Typist NEO v.13.0」
(体験版はこちらから 電子書籍 自炊 | PDF作成に最適な活字OCRソフト | e.Typist v.13.0:ダウンロード ※H24.2.8追記)
辞書機能は読取革命の方が上のようだが、表認識機能が素晴らしい。
考えてみれば、先ほどの紹介したサイトは視覚障碍者向けの記事であり、文字を正しく認識して読み上げソフトにかけることを優先していたのだろうか。いやよく分からないが。
一方私の方は会計ソフトに取り込むためのデータ作成が目的である。
いくら文字が正しく認識されていてもそれが表形式として使えなければあまり意味が無い。
いくら文字が正しく認識されていてもそれが表形式として使えなければあまり意味が無い。
ということで、現在はこの「e.Typist NEO v.13.0」を使ってデータ化に励んでいるが、実際のところどうなんだ、と。
なかなかブログで公開できる通帳のサンプルを用意するのが難しくてもどかしいところではあるが、とりあえずこちら。

これ、2001年・2002年ではなく平成01年・02年、つまり20年以上前の私の通帳。銀行名は三井銀行。
パディントンのイラストが書いてあるラブリーな通帳だ。
あのころはマルイのクレジットが苦しくて、お金が入ると入金してはすぐ引き落とされ、はぁ〜・・・(遠い目)
パディントンのイラストが書いてあるラブリーな通帳だ。
あのころはマルイのクレジットが苦しくて、お金が入ると入金してはすぐ引き落とされ、はぁ〜・・・(遠い目)
それはさておき、ちゃんと表形式の区切りとなる線が見えると思う。
これは自動認識もあるが全部自動だと厳しいので手動で引くこともある。
途中の白くなっている列は認識無効領域として設定した部分。
これは自動認識もあるが全部自動だと厳しいので手動で引くこともある。
途中の白くなっている列は認識無効領域として設定した部分。
また、表の認識だけでなく、次のように列ごとに認識できる文字種を選択できるのだが、これがまた素晴らしい。

その他細かな設定はいろいろあるが、とりあえず辞書もまっさらのまま、この状態で文字認識させて、そのままExcelへ出力したのがこちら。

「ナニコレ・・・・全然ダメじゃん・・・・」
と思うだろうが、実はデータとして使うにはそんなには悪くない。
もちろん辞書を鍛えるなどしてもう少し精度は上げる必要はあるが。
例えば日付が西暦で認識されている。
実際には平成01年02年。
クドイようだが20年以上前だ。
ちょうど大学に入った年だろうか。
あの頃はお金もなく、学校にも行かず・・・はっ、それはさておき。
西暦を和暦に直すのは後で一括置換すればOK。
実際には平成01年02年。
クドイようだが20年以上前だ。
ちょうど大学に入った年だろうか。
あの頃はお金もなく、学校にも行かず・・・はっ、それはさておき。
西暦を和暦に直すのは後で一括置換すればOK。
また、「*」などの記号も一括置換機能で消してしまえばよい。
OCRソフトにもその機能はあるし、Excel上でも可能。
OCRソフト上だと全領域(そのページの認識した文字すべて)が置換の対象となるが、Excel上だと列が選べるのでExcel上でやることが多い。
その他のゴミデータも並び替え機能などであっという間に除去できる。
相手先名や摘要の内容など言葉としておかしな部分が多少あってもあまり気にしない。
並び替えをしてるなかでコピペで簡単に直せる部分もあるし、これらが多少違っていても会計データとして致命的なものにはならない。
逆に、日付と数字(金額)、特に数字、これだけは完璧に認識してもらいたいところである。
残念ながら100%の認識は無理なのだが、数字データなのでExcelで集計して検証し修正ができる(※ 2012/08/16 解説記事を投稿)し、多少の誤認識は仕方がない。
OCRソフトにもその機能はあるし、Excel上でも可能。
OCRソフト上だと全領域(そのページの認識した文字すべて)が置換の対象となるが、Excel上だと列が選べるのでExcel上でやることが多い。
その他のゴミデータも並び替え機能などであっという間に除去できる。
相手先名や摘要の内容など言葉としておかしな部分が多少あってもあまり気にしない。
並び替えをしてるなかでコピペで簡単に直せる部分もあるし、これらが多少違っていても会計データとして致命的なものにはならない。
逆に、日付と数字(金額)、特に数字、これだけは完璧に認識してもらいたいところである。
残念ながら100%の認識は無理なのだが、数字データなのでExcelで集計して検証し修正ができる(※ 2012/08/16 解説記事を投稿)し、多少の誤認識は仕方がない。
ハッキリ言ってOCRの精度は通帳によって大きく異なる。
金融機関によっても違うし、同じ種類の通帳でも保存状態やATMでの印字の状態、スキャンの状態で違ってくる。
ひとつ、声を大にして言いたいのは、「三菱東京UFJ銀行の通帳はク◯」ということ。
この通帳だけは本当に◯ソで、嫌がらせかのようにOCRにかけづらい。
独特のフォント、列を区切る破線、破線と文字のくっつき具合など、本当に残念な通帳である。
利用者が最も多い金融機関だけに怒りもなおさら、といった感じ。
金融機関によっても違うし、同じ種類の通帳でも保存状態やATMでの印字の状態、スキャンの状態で違ってくる。
ひとつ、声を大にして言いたいのは、「三菱東京UFJ銀行の通帳はク◯」ということ。
この通帳だけは本当に◯ソで、嫌がらせかのようにOCRにかけづらい。
独特のフォント、列を区切る破線、破線と文字のくっつき具合など、本当に残念な通帳である。
利用者が最も多い金融機関だけに怒りもなおさら、といった感じ。
一方で、ツボに入るとものの見事に認識してくれる通帳もある。
例えばこちら。
例えばこちら。
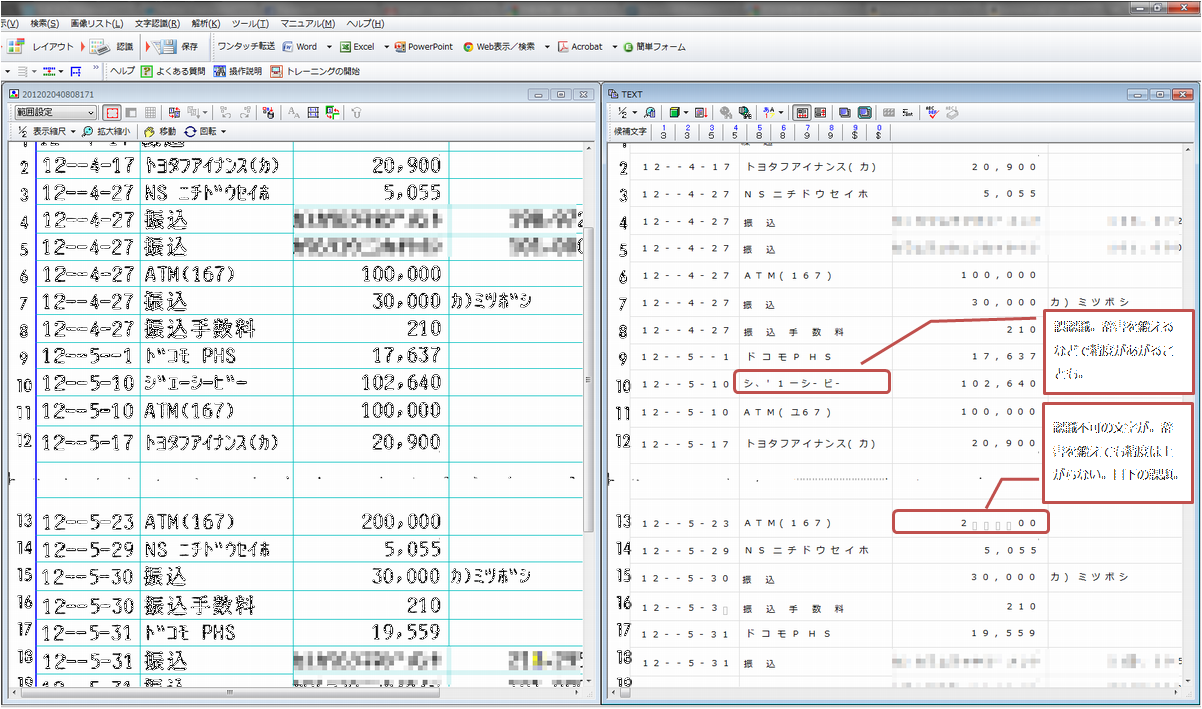
もちろん100%ではないがかなりの精度で認識されている。
ちなみにこれは10年くらい前の通帳で、第一勧業銀行のもの。
本当に三菱東京UFJ以外は今のところかなり良い感じで認識されるのでぜひ試してみてもらいたい。
なお、上記でも書いたが、精度を上げるためには次の点が重要。
- 通帳に手書きで余計なカキコミはしない!
- スキャンは高解像度でまっすぐに!
通帳へのカキコミに関しては、確かに内容をメモしておきたいということもあるかも知れないが、できればスキャンした後のPDFファイルに注釈機能でメモを取るなどで対応したいところ。
また、通帳のスキャンについてはこちらの記事を参照頂ければと。
ちなみに私はScanSnapの「スーパーファインモード・白黒」でスキャンをしている。
カラーでスキャンしてOCRソフトのカラードロップ機能で〜とかもやってみたが、イマイチ上手く行かなかったので現在は白黒で。
なお、記帳するATMによっては行や列がズレて印字されることがある。
実に腹立たしいことだが、これはもう諦めるしかないだろう。
あまり上手く認識されない場合はOCRソフト上でちまちま直すのも時間がかかるので、思い切ってそのページはExcel上でイチから入力してしまった方が早いと思う。
このように、まだ試行錯誤しながらではあるが、通帳のデータ化の道が見えてきた気がする今日この頃。
今後のOCRソフトの進化にも期待しているが、まだまだすんなり認識というわけには行かず、ある程度のデータ加工は必要だろう。
だから通帳1ページをちまちまやるのでは割りに合わないかも知れない。
複数ページあるいは同じ通帳を何冊も集めて、テンプレート機能で一気に認識・加工をしてこそ意味のある作業ではないかと。
通帳をスキャンしてアップロードしたらCSVデータになって返ってくる、というWEBサービスでも作れたらいいのだけど・・・。
せめて、ひとりでちまちまやるよりも、皆でノウハウや金融機関毎のテンプレートや辞書などを共有できたらいいなと。(あ、e.Typistはテンプレートの共有は出来なかったかも知れない・・・。)
今後のOCRソフトの進化にも期待しているが、まだまだすんなり認識というわけには行かず、ある程度のデータ加工は必要だろう。
だから通帳1ページをちまちまやるのでは割りに合わないかも知れない。
複数ページあるいは同じ通帳を何冊も集めて、テンプレート機能で一気に認識・加工をしてこそ意味のある作業ではないかと。
通帳をスキャンしてアップロードしたらCSVデータになって返ってくる、というWEBサービスでも作れたらいいのだけど・・・。
せめて、ひとりでちまちまやるよりも、皆でノウハウや金融機関毎のテンプレートや辞書などを共有できたらいいなと。(あ、e.Typistはテンプレートの共有は出来なかったかも知れない・・・。)
とりあえず今は様々な金融機関(メガバンク以外の、地銀や信金等)の通帳を試してみたいなと思っているところ。
無料モニターみたいなのを募集してみようか、なんて。
例えばDropboxでフォルダ共有しスキャンデータをアップしたもらい、こちらでOCRかけてExcelファイルで返す、みたいな。
お問い合わせはTwitter(@katocpta)のDMで、とか・・・。
無料モニターみたいなのを募集してみようか、なんて。
例えばDropboxでフォルダ共有しスキャンデータをアップしたもらい、こちらでOCRかけてExcelファイルで返す、みたいな。
お問い合わせはTwitter(@katocpta)のDMで、とか・・・。
OCRソフトの細かな設定や、Excel上での加工についてなど、また機会があれば書いてみるかも。
0 件のコメント:
コメントを投稿